Der autonome Pizzabote SAE-Level 5
Wir wiederholen die schwierige Aufgabe
vom letzten Jahr, bei der ein autonomes Fahrzeug entworfen, konstruiert
und programmiert werden soll, das selbständig kürzeste Wege in einer
übergebenen Karte plant und ausführt. Der Anwendungsfall ist ein
Lieferroboter, wie er in verschiedenen Städten erprobt wird. Das System
übernimmt hier sowohl die Rolle des Roboters (Lokalisation, lokale
Navigation mithilfe der Sensorik, Abliefern der Pizza) als auch die
der Planungsschicht, bspw. einer zentralen KI-Komponente, die auf die
Verkehrssituation der Stadt zugreifen kann und Routen nach aktueller
Verkehrslage berechnet (globale Navigation).
Und natürlich muss ein Robotersystem mit Stromversorgung, Motoren,
Getrieben, geeigneten Sensoren und Transportkapazität gebaut werden.
Falls die Probleme zu groß werden (und groß werden sie auf jeden Fall),
besteht die Fallback-Möglichkeit beim Abschlusswettbewerb mit einem
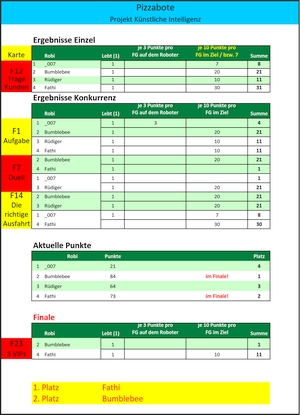
manuellen Plan zu starten. Es traten 4 Roboter zum Wettbewerb an: _007,
Bumblebee, Rüdiger
und Fathi. Das Finale Bumblebee
(84 Punkte) gegen Fathi (73 Punkte)
gewann Fathi.


Categories: AKSEN, AMS-Projekte, RobotBuildingLab
Mittwoch, Januar 22, 2020
Kombination von Imitation Learning und Reinforcement Learning zur
Bewegungssteuerung
Eine erfolgreiche Kombination von Imitation Learning (IL) und
Reinforcement Learning (RL) zur Bewegungssteuerung eines Roboters
besitzt das Potenzial, einem Endnutzer ohne Programmierkenntnisse einen
intelligenten Roboter zu Verfügung zu stellen, der in der Lage ist, die
benötigten motorischen Fähigkeiten von den Menschen zu erlernen und sie
angesichts der aktuellen Rahmenbedingungen und Ziele eigenständig
anzupassen. In dieser Masterarbeit wird eine Kombination von IL und RL
zur Bewegungssteuerung des humanoiden Roboter NAO eingesetzt. Der
Lernprozess findet auf dem realen Roboter ohne das vorherige Training in
einer Simulation statt. Die Grundlage für das Lernen stellen kinästhetische
Demonstrationen eines Experten sowie die eigene Erfahrung des
Agenten, die er durch die Interaktion mit der Umgebung sammelt.
Das verwendete Lernverfahren basiert auf den Algorithmen Deep
Deterministic Policy Gradient from Demonstration(DDPGfD) und Twin
Delayed Policy Gradient (TD3) und wird in einer Fallstudie, dem Spiel
Ball-in- a-Cup, evaluiert. Die Ergebnisse zeigen, dass der umgesetzte
Algorithmus ein effizientes Lernen ermöglicht. Vortrainiert mit den
Daten aus Demonstrationen, fängt der Roboter die Interaktion mit der
Umgebung mit einer suboptimalen Strategie an, die er im Laufe des
Trainings schnell verbessert. Die Leistung des Algorithmus ist jedoch
stark von der Konfiguration der Hyperparameter abhängig. In zukünftigen
Arbeiten soll für das Ball-in- a-Cup-Spiel eine Simulation erstellt
werden, in der die Hyperparameter und die möglichen Verbesserungen des
Lernverfahrens vor dem Training mit dem realen Roboter evaluiert werden
können.
Video: Ausführung der optimalen Policy nach 200 Lernepisoden
Kolloqium: 22.01.2020
Gutachter: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn
Download: A1-Poster,
Masterarbeit
Categories: Abschlussarbeiten, AMS-Projekte, Maschinelles Lernen