Data Challenge "Human Activity Recognition Using Smartphones Data Set" - Projektorientiertes Lernen im Master
 In der Wahlpflichvorlesung "Data Mining" im zweiten Mastersemester der
Informatik wird neben knackigen Vorlesungen und Übungen auch eine Data
Challenge geboten, bei der eine echte Datenanalyse im Team mit freier
Wahl der Mittel bearbeitet und als Paper beschrieben wird. In einem
paarweisen Review-Prozess werden die erstellten Analysen durch die
Studierenden selbst nach vorgegebenen Kriterien evaluiert.
In der Wahlpflichvorlesung "Data Mining" im zweiten Mastersemester der
Informatik wird neben knackigen Vorlesungen und Übungen auch eine Data
Challenge geboten, bei der eine echte Datenanalyse im Team mit freier
Wahl der Mittel bearbeitet und als Paper beschrieben wird. In einem
paarweisen Review-Prozess werden die erstellten Analysen durch die
Studierenden selbst nach vorgegebenen Kriterien evaluiert.
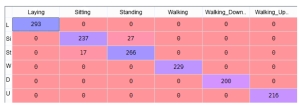
Die Aufgabe dieses Semesters ist die Konstruktion eines Modells, das die Aktivität einer Person (Sitzen, Liegen, Laufen usw.) aus den Messungen ihres Smartphones erkennt. Es sind belastbare Aussagen zur erwarteten Güte des Modells zu treffen und das Modell auf unbekannte Daten anzuwenden. Die Daten stammen aus [1] und sind vorverarbeitet, um sie leichter in Python, R oder RapidMiner laden zu können.
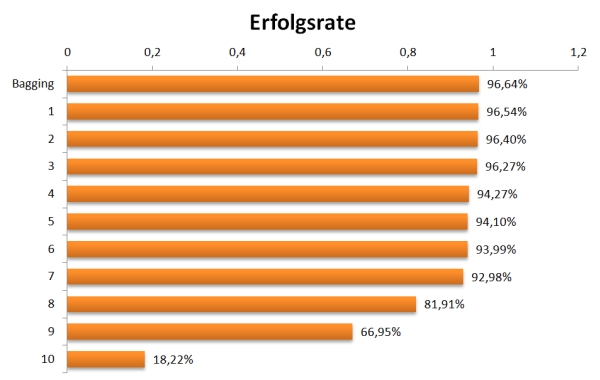
Bei den erstellten Klassifikationen gibt es kein Schummeln, denn die Lehrenden können erkennen, ob die berechneten Vorhersagen mit der Realität übereinstimmen. Dass die Studierenden die Aufgabe in der Mehrheit hervorragend gelöst haben, zeigt die Abbildung der Erfolgsraten, also der Anteil der richtig erkannten Tätigkeiten.
Abb.: Wie gut können die Teams die Tätigkeit einer Person anhand der Smartphone-Daten vorhersagen:
[1] Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra and Jorge L. Reyes-Ortiz. A Public Domain Dataset for Human Activity Recognition Using Smartphones. 21th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, ESANN 2013. Bruges, Belgium 24-26 April 2013.
Categories: Maschinelles Lernen

