Donnerstag, Februar 11, 2021
Performance-Optimierung beim maschinellen Lernen am Beispiel der
Bonitätsprüfung von Bankkunden
Die Kreditwürdigkeitsprüfung ist ein wichtiger Schritt, der von
Kreditvergabestellen durchgeführt wird und der darüber entscheiden kann,
ob das Bankinstitut potenziellen Kreditnehmern einen Kredit gewährt oder
nicht. Diese Prüfung hat einen großen Einfluss auf Agenturen,
insbesondere im Finanzsektor. Um finanzielle Probleme zu vermeiden, die
aufgrund von Risiken bei der Kreditvergabe auftreten, wird eine Methode
benötigt, die die Kreditwürdigkeitsprüfung unterstützt, indem die
statistische Leistung eines Kreditscoring-Modells erhöht wird. Mit Hilfe
von maschinellen Lernmodellen können Zeit, Aufwand und Kosten für die
Durchführung statistischer Analysen, die auf Big Data angewendet werden,
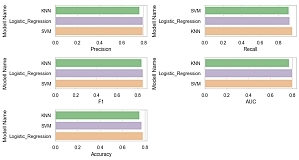
reduziert werden. Aus diesem Grund werden in dieser Arbeit Algorithmen
des maschinellen Lernens, namentlich von Logistic Regression, K-Nearest
Neighbors und Support Vector Machine, verglichen. Ferner werden
Experimente durchgeführt, die die Leistung dieser Modelle verbessern
können.

Kolloqium: 11.02.2021
Betreuer: Prof. Dr. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
Categories: Abschlussarbeiten, Maschinelles Lernen
Donnerstag, Februar 11, 2021
Entscheidungsunterstützung mit Bayesschen Netzen - Modellierung einer
COVID-19 Domäne mit HUGIN
Bayessche Netze (BN) sind gut zur Modellierung von Unsicherheit
geeignet. Ein aktuelles Beispiel für das Auftreten von Unsicherheit ist
die COVID-19 Domäne, insbesondere die Zusammenhänge zwi- schen u.a.
Symptomen, Analysen, Auswirkungen und Folgen. Nach einer kurzen
Einführung in die Grundlagen der BN sollen die we- sentlichen Konzepte
der COVID-19 Domäne einschließlich ihrer Zu- sammenhänge dargestellt
werden. Eine Analyse zum Stand der Forschung zu BN, die genau diese
Domäne bereits als Anwendung haben, schließt sich an, ebenfalls eine
eigene kurze Bewertung. Kern der Bachelorarbeit ist eine eigene
Umsetzung mit Hilfe des HUGIN-Tools.
Ergebnisse
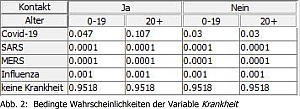
Die entstandene Anwendung ermöglicht es, die Wahrscheinlichkeit einer
Erkrankung an COVID-19, SARS, MERS oder Influenza zu bestimmen. Dafür
werden die beobachteten Symptome dem Netz als Evidenz bekannt gemacht.
Das heißt, der Wert der entsprechenden Variable wird festgelegt und ist
nicht mehr abhängig von der ursprünglichen Wahrscheinlichkeit. Es lässt
sich zeigen, dass spezifische Symptome, wie die Störung des Geschmacks
und/oder Geruchssinns, die A- posteriori-Wahrscheinlichkeiten der
Krankheiten stärker beeinflussen als häufige Symptome wie Husten.
Kolloqium: 11.02.2021
Betreuer: Prof. Dr. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
Categories: Abschlussarbeiten, Maschinelles Lernen